
Улучшенный API, по словам компании, снизит количество ошибок в словах в среднем на 54 процента, пишет TechCrunch. В некоторых областях улучшение работы будет ещё более существенным.

Важная часть обновления — новая функция в API, которая позволяет разработчикам выбирать между разными моделями машинного обучения в зависимости от конкретной задачи. Пока Google предлагает четыре модели: для коротких запросов и голосовых команд, для распознавания аудиозаписей телефонных звонков и для обработки звука с видеофайлов. Наконец, есть и ещё одна, универсальная модель, которую сервис рекомендует использовать для всех остальных случаев.
Кроме этого, инструменты распознавания речи от Google получили и новую пунктуационную модель для английского языка. По словам компании, её использование приведёт к получению намного более читаемых расшифровок: пользователи увидят ощутимо меньше длинных объединённых предложений, больше запятых, кавычек и вопросительных знаков.
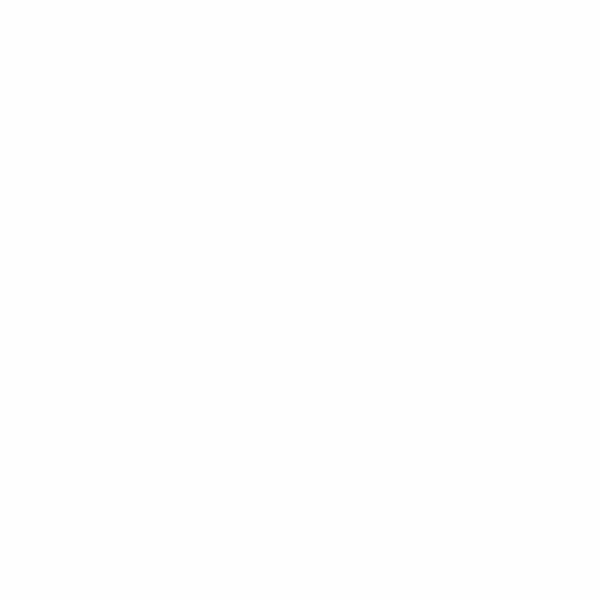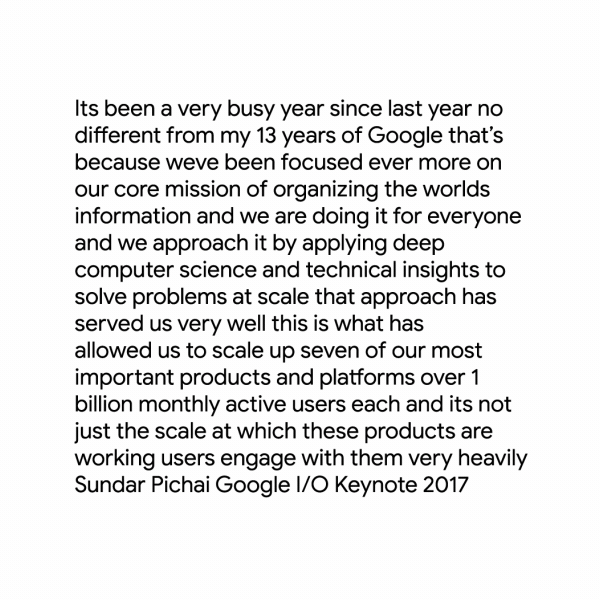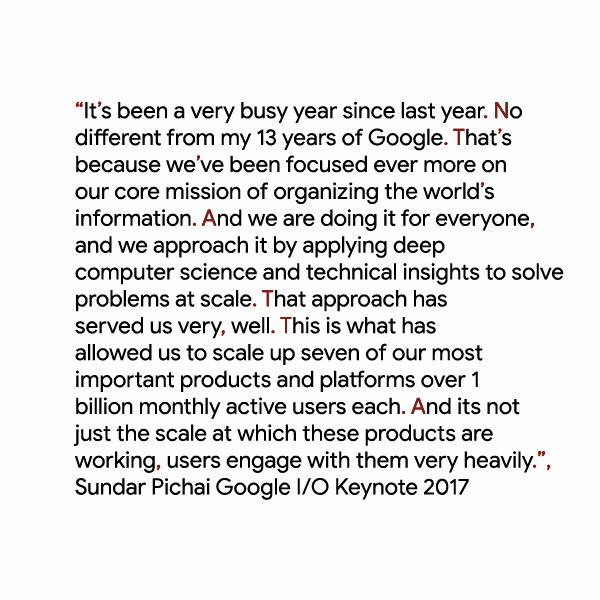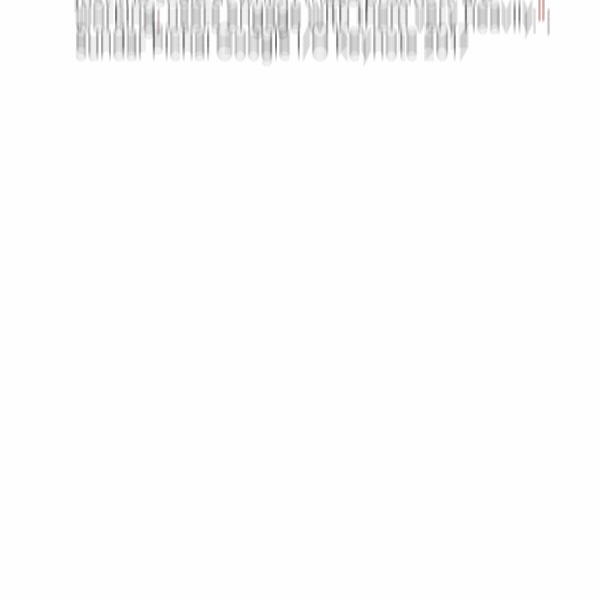
Наконец, разработчики смогут добавлять метаданные в расшифровываемые аудио- и видеофайлы — в будущем в компании планируют принимать решения о новых обновлениях на их основе.
Обработка аудио в сервисе обойдётся в $0,006 за 15 секунд. Видеомодель стоит вдвое дороже, но до 31 мая будет доступна по такой же цене.






Релоцировались? Теперь вы можете комментировать без верификации аккаунта.