О визуализации данных. Продолжение
В этом посте мы продолжаем изучать вопрос инфографики и визуализации данных. Первая часть материала лежит тут.
В этом посте мы продолжаем изучать вопрос инфографики и визуализации данных. Первая часть материала лежит тут.

В этом посте мы продолжаем изучать вопрос инфографики и визуализации данных. Первая часть материала лежит тут.
Тысяча слов. Часть вторая
Фарук Али (Farooq Ali, компания ThoughtWorks)
В сущности, визуальное кодирование — это процесс проецирования данных в наше поле зрения. Обычно это делается на двухмерных поверхностях. Для эффективного визуального кодирования требуется понимать, как же, на самом деле, работает зрение. Начнем с того, что визуальное восприятие — это процесс, включающий три этапа.
Извлечение характерных признаков
Восприятие образов
Целенаправленная обработка
На первом этапе, при извлечении признаков, миллионы нейронов работают параллельно, чтобы определить первичные визуальные признаки, такие, как форма, цвет и движение. Это лучше пояснить на примере. Сколько троек вы видите в следующем наборе цифр?
Сколько времени на это потребовалось? Троек пять. А теперь попробуем снова.
Очевидно, во второй раз получилось гораздо быстрее, благодаря сокращению первого этапа — извлечения характерных признаков. Ваша зрительная система освободила вас от части мыслительной работы, а именно — от «преаттентивной обработки». Придание элементам более светлого или более темного тона (то есть, изменение интенсивности цвета) — один из способов визуального кодирования информации для подпороговой обработки. Поэтому, интенсивность цвета часто характеризуется как «преаттентивный атрибут». Почему же в первый раз отыскать тройки было сложнее? Дело в том, что контуры чисел — это сложные объекты, которые мозг не может обрабатывать преаттентивно. В книге «Визуализация информации: визуальное мышление в дизайне» Колин Уэйр (Information Visualization: Visual Thinking for Design, Colin Ware) упоминает семнадцать преаттентивных атрибутов. Самые важные из них были отобраны Стивеном Фью в книге «Дизайн информационных панелей» (Information Dashboard Design, Stephen Few) и приведены на следующем рисунке.
На втором этапе — распознавание образов — наш мозг сегментирует визуальный мир на отдельные зоны и обнаруживает структуру объектов, а также связи между ними. Только на третьем этапе начинается обработка информации при помощи механизмов, связанных с вниманием. Здесь уже решаются аналитические задачи.
Наша цель — достичь максимального результата на двух первых этапах, то есть, делегировать часть задач от мышления к преаттентивному восприятию. Если данные будут передаваться в форме крупных визуальных «информационных глотков», то мы будем более эффективно воспринимать эти данные.
Оказывается, что эффективность упомянутых выше атрибутов варьируется в зависимости от типа данных, которые требуется закодировать. Итак, как же не ошибиться с выбором?
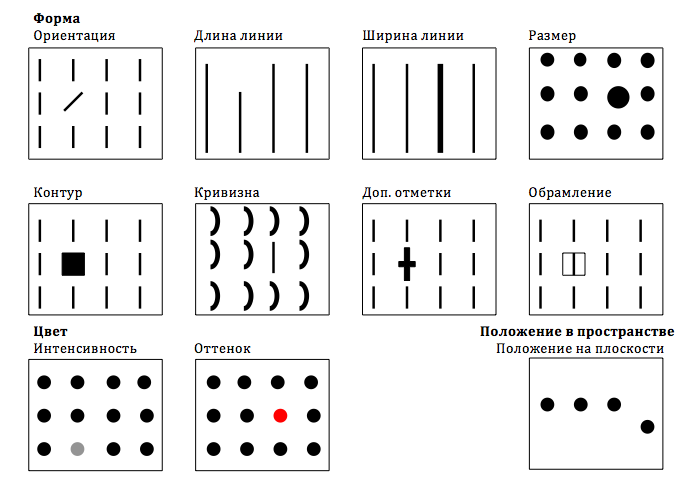
Преаттентивные атрибуты по Стивену Фью
Мне показалось, что оценка по Маккинли (на следующем рисунке) лучше всего проясняет интересующую нас концепцию, поскольку такая оценка учитывает, как эффективность отличается в зависимости от типа данных.
Для людей вроде меня это настоящий Святой Грааль визуального дизайна. Не пожалейте времени на внимательное изучение этих рейтингов и соотнесите их с собственным опытом. Как видите, положение на плоскости (2D position) занимает верхнюю строчку во всех трех вариантах рейтинга. Именно поэтому традиционные Декартовы координаты настолько удобны для представления самой разной информации. Кроме того, обратите внимание, как длина и плотность (выше мы называли плотность «интенсивностью цвета») варьируются для количественных и порядковых данных. Именно этот факт был использован в приведенном выше примере при сравнении силы бренда и различных городов.
Давайте вооружимся этими рейтингами и развенчаем расхожий миф об эффективности круговых диаграмм для количественных сравнений. Отнюдь, согласно рейтингам, длина и положение всегда оказываются эффективнее площади и угла.
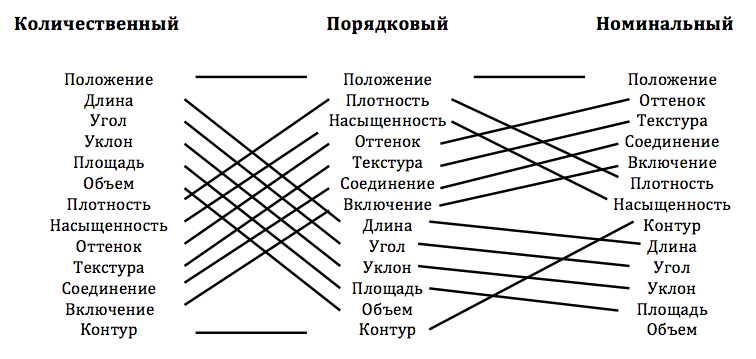
Рейтинги по Маккинли
Судите сами: можете ли вы сказать, воспользовавшись приведенной ниже круговой диаграммой (Стоимость разработки различных функций программы), разработка какой функции в составе программы обойдется дороже всего?
Пожалуй, не сможете. Ответить на этот вопрос будет гораздо проще, воспользовавшись приведенной рядом столбчатой диаграммой. Действительно, круговые диаграммы хорошо иллюстрируют отношения типа «часть-целое». Например, из круговой диаграммы хорошо видно, что на разработку трех основных функций уйдет примерно 25 процентов бюджета — но на этом все заканчивается. Если поставленная задача требует большего количества информации, которая не менее важна в конкретном случае (например, требуется сравнить и ранжировать части), то кодировать данные потребуется иначе.
Выбор наиболее эффективного варианта кодирования во многом зависит от конкретной задачи. Поэтому, и рейтинги кодирования нужно рассматривать именно под таким углом. Не забывайте также, что при кодировании данных определенного типа можно использовать более одного визуального канала, чтобы решить задачу более эффективно. Например, количественное значение температуры можно кодировать при помощи длины, оттенка (от синего до красного) и интенсивности (от светлого до темного в обоих направлениях — в «горячую» и «холодную» сторону).
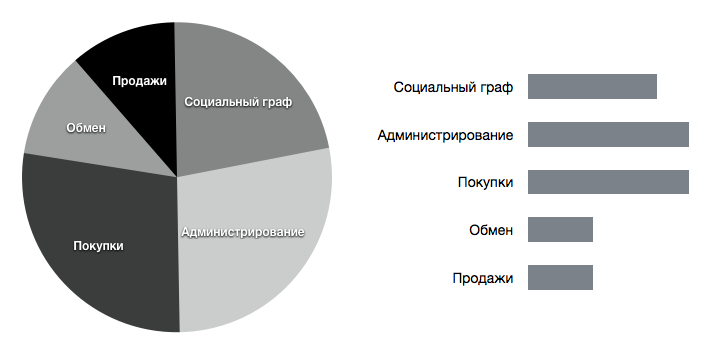
Стоимость разработки функции в составе программы
Гештальт-принципы для визуального восприятия очень полезны для группирования, связывания и различения информации в ходе визуализации. Здесь начинается вторая стадия работы нашей зрительной системы — распознавание образов. Например, вы можете направить взгляд пользователя, чтобы он просматривал информацию в горизонтальном или в вертикальном направлении. Для этого просто нужно немного увеличить отступы — соответственно, горизонтальные или вертикальные — чтобы помочь зрителю сгруппировать информацию на преаттентивном уровне. Этот феномен объясняется гештальт-принципом «близости» (proximity). В соответствии с ним, те объекты, которые находятся ближе друг к другу, воспринимаются как элементы из одной группы. Либо можно просто сгруппировать элементы при помощи линий и границ, используя принцип обрамления (enclosure). Шесть гештальт-принципов лучше понятны на примере.
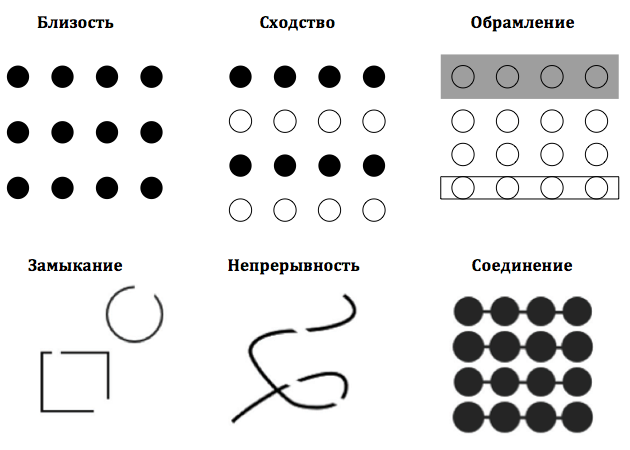
Гештальт-принципы распознавания образов
Близость: мы видим три ряда точек, а не четыре столбца, поскольку по горизонтали точки расположены ближе, чем по вертикали
Сходство: схожие объекты мы воспринимаем как относящиеся к одной и той же группе
Обрамление: мы группируем первые четыре и последние четыре точки как две отдельные строки, а не воспринимаем все восемь точек отдельно.
Замыкание: мы автоматически замыкаем квадрат и круг, а не усматриваем три отдельные линии
Непрерывность: мы видим одну непрерывную линию, а не три, проведенные произвольно
Соединение: мы воспринимаем соединенные точки как относящиеся к одной группе.
Причина исключительной эффективности графиков рассеивания в том, что они помогают нам замечать корреляции в наших данных. Это объясняется тем, что законы близости, непрерывности и сходства помогают нам группировать информацию и заполнять в ней пробелы. Визуализация, описанная в знаменитой лекции Ханса Рослинга на конференции TED, помогла по-новому взглянуть на проблему бедности. Соответствующий график показан ниже.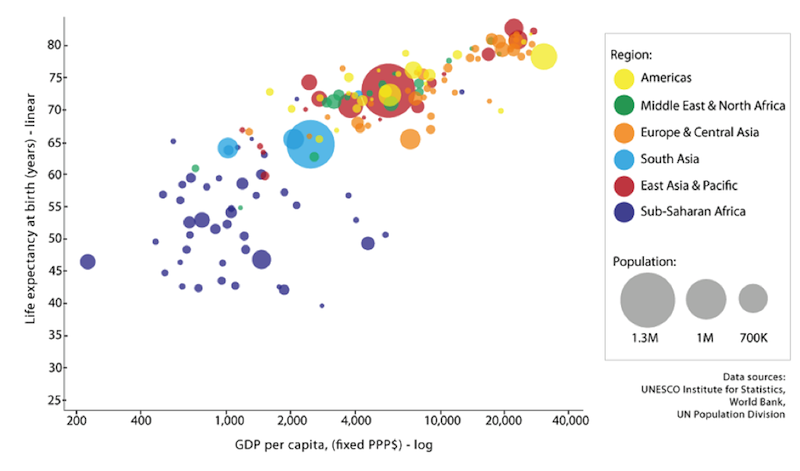
Гештальт-принципы, применяемые для обнаружения корреляций в графиках рассеяния
Обратите внимание — точки на графике сами собой складываются для нас в линию. Несмотря, на «помехи», вызванные вариативностью, мы без труда визуально выстраиваем определенные корреляции между доходом на душу населения и ожидаемой при рождении продолжительностью жизни. Корреляция становится еще более явной, когда визуализация демонстрируется на движущейся схеме, показывающей изменения с течением времени. Если вы еще не видели эту лекцию, рекомендую потратить на это время и задаться вопросом — а могли бы вы сделать такой же содержательный доклад, оперируя лишь словами и цифрами?
Как и в ходе любого качественного процесса разработки программного обеспечения, при работе очень важна обратная связь. В рамках этой статьи мы не можем обсудить процесс организации обратной связи при софтверной разработке вообще. Но, применительно к визуализации данных, можно провести некоторые виды совершенно объективного пользовательского тестирования. Вот некоторые соображения по этому поводу:
Внедряйте обратную связь в рабочий процесс на очень раннем этапе. Занимайтесь такой работой часто, на протяжении всего процесса разработки. Используйте при этом визуальные прототипы. Не пытайтесь разработать «Совершенную визуализацию» за семью замками, так как можно пышно представить готовое решение, совершенно неприменимое в данной предметной области.
Целесообразно измерять время, требуемое для решения мелких задач, из которых состоит более общая предметная задача. В таком случае, вы сможете протестировать несколько различных вариантов визуального кодирования для работы с одной и той же информацией.
Постарайтесь создать набор тестовых сценариев для различных множеств данных, чтобы проверить, насколько отличается эффективность варианта кодирования в зависимости от конкретной задачи.
Хотя, мы и не затрагиваем тему качества и истинности визуализируемых данных, не забывайте, что данные и параметры действительно бывают неверными (помните? «Есть ложь, святая ложь и статистика»). Соответственно, к ним нужно относиться с долей скептицизма. В данном случае, хорошими примерами являются показатели, применяемые при измерении качества кода и в управлении проектами. Иногда бывает более важно обнаружить тенденции и отклонения от них, а не абсолютные значения. В этом и заключается сила визуализации информации.
Наконец, учитывайте, что в пользовательских отзывах всегда присутствует субъективизм, обусловленный эстетическими предпочтениями и личным мнением.
Третья и заключительная часть материала выйдет через неделю






Релоцировались? Теперь вы можете комментировать без верификации аккаунта.