Когда редакция Девбая готовит к выпуску материал, в котором ожидается куча статистики, различных циферок и процентов, то пытается систематизировать такую информацию удобным для понимания способом — с помощью графиков. Скромные возможности Numbers вполне подходящи в этом деле, но принятая во внимание критика жж-юзера 9zloy, более известного как Михаил Дубаков, подтолкнула нас к изучению вопроса инфографики и визуализации данных.
Когда редакция Девбая готовит к выпуску материал, в котором ожидается куча статистики, различных циферок и процентов, то пытается систематизировать такую информацию удобным для понимания способом — с помощью графиков. Скромные возможности Numbers вполне подходящи в этом деле, но принятая во внимание критика жж-юзера 9zloy, более известного как Михаил Дубаков, подтолкнула нас к изучению вопроса инфографики и визуализации данных.
Тысяча слов. Часть первая
Фарук Али (компания ThoughtWorks)
Добывать данные в наше время уже не сложно. Сложно их понимать. Twitter за минуту пополняется примерно на 36 000 записей. Tesco генерирует более 2 миллионов записей об операциях над данными ежедневно. За то время, которое уйдет у вас на прочтение этой страницы, пользователи YouTube загрузят в Сеть более 20 часов видео. И чем больше компаний интегрируют в свои системы возможность работы с семантическим Вебом, тем сложнее становится правильно интерпретировать окружающую нас информацию.
Наша компания сейчас очень много работает над тем, чтобы помочь клиентам интегрировать эти системы, упростить их и извлечь из них выгоду. То же касается огромных объемов данных, содержащихся в этих системах. Для этого активно применяется визуализация информации — сокращенно «infovis». Визуализация информации будет играть все более существенную роль в работе с избытком данных. Мощная комбинация изображений, слов и чисел — подобранных верно — может обеспечить наиболее полное понимание ваших данных. Вопрос в том, как добиться такой волшебной комбинации? Распространенное заблуждение заключается в том, что эту проблему лучше смогут решить дизайнеры или другие члены команды с эстетическими склонностями. Хотя, в данном случае и требуется креативное мышление, творческий хаос дизайнерских мыслей необходимо упорядочивать. Иными словами, требуется структурированный подход к проблеме визуализации, при котором форма подстраивается под содержание. Команда, использующая визуальную информацию и специально выстраивающая процесс проектирования визуализации, несомненно, движется к созданию более инновационных и ценных программ.
В этой и следующих статьях мы хотели бы развеять ореол таинственности, окружающий визуализацию информации и поделиться некоторыми соображениями структурного плана, применяемыми при проектировании визуализации. Надеемся, эти материалы простимулируют вас лучше разобраться в визуализации информации и найти общий язык с коллегами. Так вы сможете придумывать и создавать более качественные графические схемы.
1. Запах кофе*
*Известно, что запах кофе нейтрализует другие запахи. Так, в хороших магазинах парфюмерии посетителю предлагается нюхать молотый кофе, чтобы отвлечься от аромата одних духов и «с чистого листа» оценить следующие. Вероятно, автор сравнивает этот раздел с запахом кофе именно по такой аналогии — отвлекитесь от предыдущих впечатлений и настройтесь на тему — прим. пер.
Многие проблемы визуализации информации изучаются в ходе научных и академических исследований. И это хорошо, поскольку визуализация информации непосредственно связана со зрительной перцепцией человека. А за последние сто лет наука немало узнала о природе этого механизма.
Печально, но мы не можем, положа руку на сердце, утверждать того же об ИТ-индустрии. Дело в том, что прогресс в этой сфере движется не столько объективными исследованиями, проводимыми в предметной области, сколько контактами между производителями ПО и директорами по инвестициям. Зачастую эти события разворачиваются на лужайке для гольфа. ИТ-индустрия достигла несомненного прогресса в работе с данными — их сборе, очистке, преобразовании, интеграции и хранении данных. Но мы не можем сказать того же об анализе таких данных с акцентом на их «человеческую составляющую». Суровая правда заключается в том, что многие инструменты для бизнес-аналитики не выдерживают никакой критики при оценке в свете актуальных исследований визуальной перцепции (восприятия), дизайна и эффективной визуальной коммуникации.
Как верно заметил знаменитый американский журналист Дэниел Пинк, «существует огромная разница между тем, что знает наука, и что делается в бизнесе». В итоге, многие из нас вынуждены мириться со сложившимся статус-кво: доминированием табличных приложений, круговых диаграмм и постраничная разбивка информации. Многие, но не все. Стивен Фью, живой классик в области визуализации бизнес-информации, замечает: «Редкостная вещь удручает меня так же сильно, как хорошее исследование по визуализации данных, которое действительно помогло бы решить реальные проблемы — но не используется, так как никто не рассказал о нем кому следует, либо рассказал, но совершенно непонятным образом».
Тем не менее, поводы для оптимизма имеются. Визуализация информации — не такая новая область. Визуальная передача информации известна человеку с тех пор, как мы начали рассказывать друг другу истории. И именно сейчас наступает всплеск интереса к визуализации информации, к эффективному использованию ее методов новыми глубокими способами, чтобы справиться с потоком данных, обрушившимся на нас в наш Век Информации. Во многих отраслях промышленности и организациях уже ясна вся ценность визуализации данных и то, насколько ее приемы могут помочь в решении нетривиальных проблем.
Когда в ThoughtWorks приходится оценивать крупномасштабные айтишные проекты, сталкивающиеся с трудностями, мы сразу обращаемся к наиболее актуальным внутрикорпоративным количественным исследованиям качества создаваемого ПО (internal software quality measurement), а также к визуализации данных. Это помогает нам оценить степень текущего «здоровья» рассматриваемой системы. Можете себе представить, что настолько сложно структурированная информация — хитросплетение архитектур, сотни тысяч линий кода и накопленные за годы работы результаты человеческих решений плюс история реализаций — не так легко поддается анализу. Вот почему мы полагаемся на проверенные методы визуализации данных, чтобы понять, что помогает топ-менеджерам принимать правильные решения.
Аналогично, газета «Нью-Йорк Таймс» завоевала репутацию издания, пишущего содержательные статьи на самые разные темы, так как все сюжеты и взаимоотношения эта газета подает в свете текущих событий. Наиболее успешные из современных компаний, занимающихся бизнес-анализом в розничной торговле — в частности, фирмы, реализующие программы лояльности — активно пользуются визуализации данных. Благодаря этому, работники розничной торговли могут почти идеально оценивать, продвигать и размещать продукты в магазинах, поскольку учитывают покупательские привычки клиента и стимулируют лояльность. А в наше время, со все большим распространением устройств с сенсорными экранами и малоэкранных пользовательских интерфейсов, мы вынуждены искать еще более инновационные способы визуализации информации.
Итак, рассмотрим некоторые беспроигрышные принципы проектирования при визуализации информации.
2. Принципы проектирования при визуализации
«Доказательства есть доказательства, будь то слова, числа, изображения, схемы, как статичные, так и динамичные», — считает Эдвард Тафти, гуру в области дизайна и визуализации информации. «Неважно, к чему относится та или иная информация, тот или иной контент. Важно, что все это — информация». Цель визуализации информации — помочь нам мыслить более продуктивно и более эффективно анализировать информацию. Говоря о том, как достичь этих целей, следует помнить о следующих принципах:
Повышайте плотность информации. Не все элементы визуализации несут смысловую нагрузку. Схемы — особенно те, что автоматически генерируются программами Microsoft — бывают наполнены так называемым «графическим хламом» (chart junk). Это визуальные элементы, не несущие никакой информационной нагрузки. Кроме того, этот принцип можно трактовать в контексте оптимизации «информационно-графического соотношения» (data-ink ratio). Иными словами, это соотношение графики (скажем, краски или пикселов), кодирующей значимую информацию, и общего количества информации (пикселов). В данном случае, типичными плохими примерами являются объемные столбчатые диаграммы, бесполезные рисунки в качестве фона, излишние линии сетки и злоупотребление пиктограммами. Поэтому, боритесь с лишними примочками и более рационально используйте каждый пиксел.
Активнее используйте образное мышление. Человеческое зрение специально заточено под распознавание узоров и закономерностей во всем, что вы видите. Это происходит гораздо раньше, чем вы начинаете «думать» о визуальной информации (то есть, сознательно ее обрабатывать). Если мы правильно представим нашу информацию, максимально эффективно задействовав при этом наш врожденный механизм зрительного распознавания, то наш зритель сможет анализировать информацию более эффективно, думая при этом меньше. В этом и заключается суть «человеко-ориентированного» анализа, а также основная тема данной статьи. Мы рассмотрим, как структурированный подход к проектированию визуализаций помогает максимально задействовать визуальное мышление и повысить продуктивность анализа информации.
Контент как уровень взаимодействия. Визуальное мышление связано со считыванием, то есть, потреблением информации. Но потреблением информации работа не ограничивается. Мы же хотим взаимодействовать с нашими данными. С точки зрения «человеко-ориентированного» подхода, это требует создания естественных интерфейсов, обеспечивающих эффект присутствия. Когда вы работаете с картами Google Maps на iPhone и iPad, жесты щепка, смахивания и нажатия на карту кажутся естественными. Непосредственная манипуляция и мгновенный отклик карты — пример ситуации, в которой взаимодействие с интерфейсом осуществляется на уровне контента. Этот принцип применим и в интерфейсах, управляемых при помощи мыши, хотя и не так эффективен. К взаимодействиям на уровне контента относятся определяемые контекстом всплывающие подсказки, подсвечивание ссылок, графические накладки и анимированные переходы. Цель этого принципа — сделать контент центром внимания, до такой степени, что ваш инструментарий словно исчезает.
3. Процесс проектирования дизайна
В основном, процесс проектирования визуализации касается всех этапов рабочего потока разработки программного обеспечения. В конце концов, визуализация информации — это просто процесс преобразования данных в интерактивные визуальные представления, либо в коде, либо при помощи инструментов. Целый ряд специалистов специально занимались разработкой структурированных процессов создания визуализаций. В итоге получились такие концепции, как «Конвейерная модель» (Pipeline Model, Агравала), «Циклическая модель» (Cyclical Model, Вийк) и «Вложенная модель» (Nested Model, Мунцнер). Поскольку некоторые подобные процессы впервые были описаны в исследовательских статьях, они могут показаться чрезмерно сложными (как минимум, среднему читателю-специалисту). Может даже создаться впечатление, что авторы из кожи вон лезли, чтобы впечатлить читателя (один из них даже применил математический анализ!).
Итак, если отвлечься от излишней сложности, суть процесса проектирования визуализации показана на следующем рисунке:
Процесс проектирования визуализации
Определение предметных задач
Качественная визуализация всегда начинается с постановки задач, которые требуется решить. Это делается на языке конкретной области, к которой относятся решаемые задачи. Например, Agile-методология использует для формулирования требований так называемые «пользовательские истории». Пример такой истории: «Я — преподаватель. Меня интересует, насколько хорошо студенты успевают по моему предмету, чтобы можно было соответствующим образом спланировать промежуточную зачетную сессию».
Абстрагирование задач
Разумеется, успеваемость студентов по предмету можно измерить несколькими способами. Возможно, вы захотите оценить среднюю успеваемость всей группы. Может быть, вас интересует распределение различных оценок среди студентов, либо в зависимости от темы, либо во времени. А может быть, вы захотите проверить, кто отсутствовал на занятии по определенной теме, которой не оказалось в конспекте у студента. Может потребоваться узнать, какие темы вызвали у студентов наибольшие сложности. Усматриваете сходство между задачами, стоящими перед преподавателем, и задачами менеджера проектов, финансового аналитика, либо любого другого специалиста, чья производительность определяется ежедневной выработкой? Аналитические задачи обычно представляют собой лишь отдельные образцы или смесь нескольких хорошо известных абстрактных задач, осуществляемых над одним или несколькими параметрами. В основном, речь идет о следующих задачах:
Фильтрация. Нахождение данных, удовлетворяющих определенным условиям
Нахождение экстремумов. Получение данных с максимальным и минимальным значением
Сортировка. Ранжирование данных по определенному показателю
Определение диапазона. Конкретизация разброса значений данных
Нахождение аномалий. Обнаружение отклонений и данных с неожиданными значениями
Характеристика распределения: Определение того, как данные распределены в диапазоне всей доступной информации
Кластеризация. Группирование схожих элементов
Корреляция. Распознавание взаимоотношений между информацией двух типов
Сканирование. Быстрый обзор множества элементов
Операции над множествами. Нахождение пересечений и объединений множеств
Нахождение значения. Поиск конкретного значения на основании определенных критериев
Цель абстрагирования задач — разбиение предметной задачи на множество низкоуровневых задач или операций. Желательно, чтобы они были ранжированы по приоритету, если это возможно. Как мы увидим ниже, визуальное кодирование ваших задач, фактически, сильно зависит от решаемых аналитических задач.
Абстрагирование данных
Сколько характеристик температуры воды вы сможете мне назвать? По цвету крана — уже две: вода бывает горячая и холодная. Кроме того, вы можете сказать, что вода кипящая, тепловатая, либо замерзшая. А можете просто назвать температуру по Цельсию или по Фаренгейту. А вот в каком порядке вы расположите слова «горячая» и «холодная»? Какая характеристика в ряду «кипящая», «холодная», «тепловатая», «горячая» и «замерзшая» пойдет первой? А теперь попробуйте упорядочить значения -1°C, 10°C и 4°C. Способ представления информации оказывает огромное влияние на ее когнитивную обработку — особенно при визуализации данных. Прежде, чем приступить к визуальному кодированию данных, нужно понять природу каждого параметра (типа данных), представленного на схеме. Существует три основных типа данных, в которым нам нужно разбираться.
Номинальные данные (nominal data). Это категориальные данные, порядок которых не имеет значения. Например, это могут быть яблоки в отличии от апельсинов; а также отделы продаж, отделы разработки, отделы маркетинга, отделы бухгалтерии и учета.
Порядковые данные (ordinal data). Это данные, порядок которых важен, а степень различия между отдельными значениями — нет. Например, удовлетворенность пользователя, которая может быть охарактеризована как «очень доволен», «доволен», «равнодушен», «недоволен» или «очень недоволен» не показывает, насколько степень недовольства одного пользователя отличается от степени недовольства другого. Аналогично, когда мы определяем призеров гонки как «первого», «второго» и «третьего», это не показывают разницу времени, отделяющего призеров друг от друга.
Количественные данные (quantitative data). Это числовые данные, в которых важна разница между отдельными показателями: например, 1 см, 10 см и 20 см. Количественные данные иногда классифицируются далее на интервальные данные и данные о соотношении. Это делается, чтобы подчеркнуть существование точки 0, но здесь мы не будем вдаваться в такие сложности.
Иногда мы принимаем решение преобразовать типы данных из нашего информационного множества, основываясь на абстракциях стоящих перед нами задач. Вы можете спросить — почему и в каких случаях может возникать такая необходимость? Ниже описаны два распространенных сценария.
Задача требует сделать определенные предположения о порядковых данных, с целью агрегации информации — например, для расчета средних значений и сумм. Например, команда Agile-разработчиков может присвоить пользовательским историям количественные значения, в зависимости от планируемых трудозатрат на каждую историю. И это будет делаться в геометрической прогрессии, по такому же принципу, как оценка размера футболки: S = 1, M = 2, L = 4, XL = 8. Так можно количественно выразить объем задач по проекту.
Для эффективного выполнения задачи не требуется особой точности. Например, чтобы определить, какие сотрудники поздно прислали свои листы учета рабочего времени, не требуется знать, насколько опоздала та или иная отправка. Здесь мы касаемся степени совершенства дизайна и понимаем, почему так важно четко формулировать задачи. Такие компании, как Apple, добились больших успехов в этой области, так как разделяют следующее мнение: «Художник знает, что достиг совершенства не тогда, когда уже нечего добавить, а тогда, когда больше нечего отнять» (Антуан де Сент-Экзюпери)
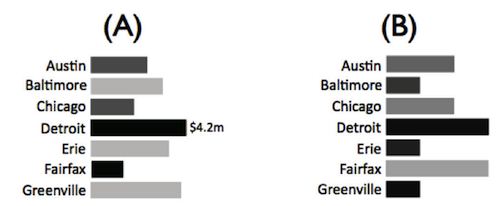
Понимание ваших типов данных и выбор правильного уровня абстрагирования (то есть, тех самых типов) вашего множества данных в зависимости от поставленных задач — вот ключевые составляющие эффективной визуализации данных. Например, на следующем рисунке показано два способа представления силы бренда вашей компании (слабый, средний, сильный) и выручки в зависимости от города. Не имея дополнительной информации о столбчатой диаграмме слева (А), можете ли вы угадать, в каком городе вы имеете максимальные прибыли при минимальной силе бренда?
Вероятно, вы выбрали Гринвилл, так как ему соответствует самая длинная из светлых полос. Здесь срабатывает несколько факторов. Во-первых, человек интуитивно ассоциирует колебания в интенсивности цвета (яркость или темноту какого-либо оттенка) с порядковыми данными (силой бренда). Кроме того, наш глаз очень хорошо приспособлен для различения интенсивности цвета (до определенной степени). Кроме того, наша зрительная система отлично настроена на то, чтоб улавливать тончайшие отличия в длине объектов. Поэтому, длина приобретает очень большое значение при визуальном представлении (другими словами — кодировании) количественных типов данных. В данном случае, речь идет о выручке. Если бы я поменял местами варианты визуального кодирования и применил схему из варианта B, где длина означает силу бренда, а интенсивность цвета — размер выручки, то решить поставленную выше задачу было бы гораздо сложнее или вообще невозможно.
На самом деле, можете попробовать задать любой вопрос по этим данным — и первый вариант визуализации неизменно будет более удобен для ответа, даже если дать подробную легенду по чтению второго варианта. Эффективное использование нашего зрения для стремительного восприятия информации, на основе абстрагирования задач и данных, позволяет укладывать больше информации в меньшем пространстве, а также замечать закономерности, которые в противном случае пришлось бы обрабатывать в левом полушарии мозга. (Левое полушарие отвечает за аналитические и последовательные задачи). Именно такого «разделения труда» мы стремимся достичь на следующем этапе работы, в ходе визуального кодирования.








Релоцировались? Теперь вы можете комментировать без верификации аккаунта.