
Решения НР software позволяют увидеть редкие проблемы сети, те сетевые баги, которые чреваты последствиями. Мы можем увидеть все события, куда они могут вести, какими изменениями вызваны и т.д., — программа сама сопоставляет эти события и показывает слабые и проблемные места сети. С помощью этих инструментов мы можем увидеть сетевую проблему, еще до ее перехода в критическую фазу.
О том, как решение НР Software по аналитике позволяет выявить скрытые проблемы сети и бизнес-приложений и многом другом, под катом
Программные решения, как IT-менеджмент, представляют собой широкий спектр продуктов, который включает много интересных решений для автоматизации управления ИТ, автоматизации процессов, решения задач мониторинга, управления дата центрами.
Сегодня мы поговорим о решениях, предназначенных для мониторинга: мониторинга не только ИТ 'железа', а и бизнес-сервисов, то, что, собственно говоря, интересует бизнес.
Сейчас ни для кого не секрет, много компаний строят свой бизнес опираясь на IT. Руководителей мало интересует, что происходит с отдельным сервером, с отдельной ‘железкой’. Интересует, в первую очередь, качество предоставляемых сервисов, удовлетворенность клиентов, и возможность работы бизнес-сервисов на высоком уровне и таким образом обеспечивать непрерывную работу компании.
Соответственно, когда ухудшается наш сервис, (одно дело, если это внутренний клиент или внутренний пользователь, он может потерпеть немного), если же это клиент банка, телекома, или неважно какой компании, когда он сталкивается с плохим сервисом, что он делает? Он идет к конкуренту.
Таким образом, одна из основных задач такого рода мониторинга — это дать гибкий инструмент, который позволит связать те события, которые происходят в IT с состоянием бизнес-сервисов, возможность предсказать проблемы, возможность автоматизировать устранения проблемы для восстановления сервиса как можно быстрее и как можно качественнее. Следовательно, когда мы гарантируем нашим клиентам и заказчикам качественный сервис, они продолжают с нами работать, прибыли растут, мы захватываем все больше рынка, и выглядим красиво по сравнению с нашими конкурентами.
Что компания Hewlett-Packard предлагает для решения подобных задач? В общем, у НР достаточно широкий портфель, НР занимается решениями для мониторинга уже более 25 лет, начали с сетевого мониторинга, Network Node Manager, может быть кто-то об этом знает, потом был разработан целый ряд интереснейших решений, некоторые решения попали в НР за счет их покупки у других компаний, которые являлись лидерами в той или иной отрасли.
Решения НР Software
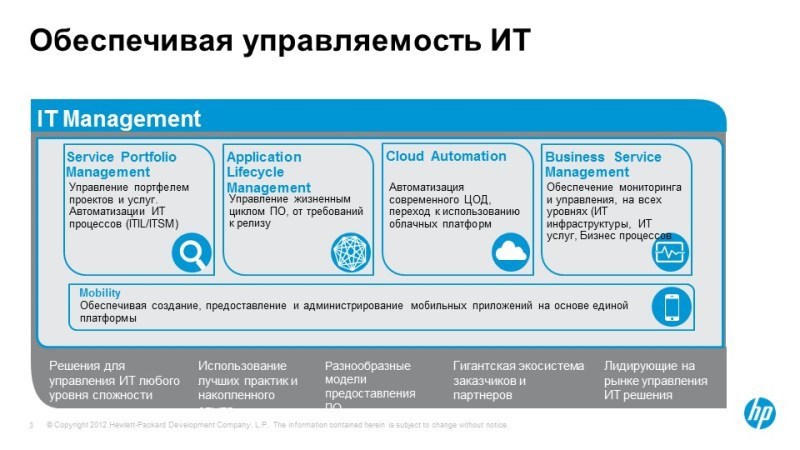
Если обобщить, то можно разбить предлагаемые решения на 4 категории:
Первый самый простой и понятный – инфраструктурный мониторинг (инфраструктурный менеджмент), здесь речь идет о мониторинге сетей, серверов, программного обеспечения, т.е. ИТ-ресурсов. В принципе, у многих компаний эти задачи уже решены коммерческими или бесплатными средствами. Например, Nagios, Zabbix используют Microsoft, поэтому мы не будем сейчас на этом останавливаться.
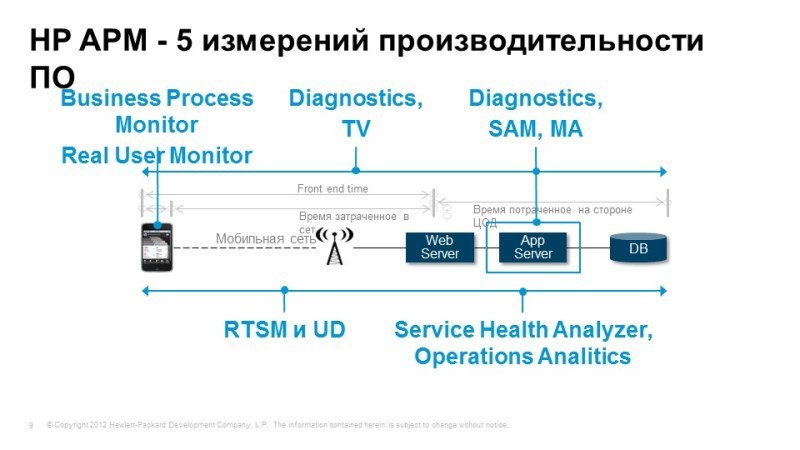
Речь пойдет больше о таких вещах, как Application Performance Management – это возможность выполнять комплексный мониторинг доступности приложений, и соответственно все, что под ним находится, мониторинг с точки зрения конечного пользователя, возможность диагностики проблем, которые находятся внутри application.
Далее Operations Bridge — непривычное название, Зонтик, зонтичная система мониторинга, которая позволяет объединить в себе данные мониторинга и самых разнообразных средств из имеющихся или новых, и создать единую консоль. Служба мониторинга – это консоль, которая предоставляет единое представление о том, как себя чувствуют сервисы, рассчитывается QPI, туда сваливаются все события, метрики производительности.
И Operations Analytics — это новейшая разработка HP, которая вышла на рынок чуть больше года назад, это решение, которое позволяет находить малоизвестные проблемы.
Когда мы говорим про традиционный мониторинг, мы знаем что мы хотим измерять, чаще всего знаем, каким должно быть пороговое значение, т.е. мы ищем те вещи, которые уже знаем, те сбои, которые ожидаемы. Например, известные события в логах, контролируем важные для нас параметры производительности или доступности сервисов, для которых тоже задаем пороговые значения.
На самом деле, в ИТ-инфраструктуре крупного предприятия происходит множество событий, которые не можем контролировать все. Когда мы говорим, допустим, о телефон-операторах, у которых количество логов растет гигабайтами в день, предусмотреть все возможные сценарии развития событий сложно, Operations Analytics использует методы обработки BigData, методы искусственного интеллекта для выявления нестандартных проблем, для поиска тех сбоев, которых не было раньше, нестандартных решений.
Платформа uCMDB
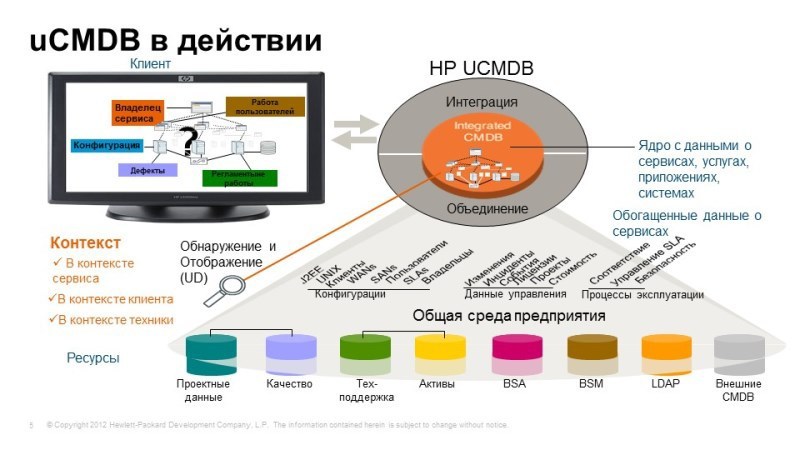
Прежде чем мы перейдем к рассмотрению этих продуктов, нужно сделать небольшое лирическое отступление, упомяну uCMDB — универсальная конфигурационная база данных, она является одним из ключевых компонентов не только для решений мониторинга, но и в других решениях для управления ИТ производимостью.
Итак, что она из себя представляет: это единая конфигурационная база данных, которая позволяет выстроить модели сервисов, объединив все компоненты, взаимосвязи, взаимные влияния, т.е. создать единую точку предоставления сервиса: из чего он состоит. uCMDB является связующим звеном между решениями мониторинга, если мы говорим про мониторинг, то на uCMDB, на отдельный объект мы можем «повесить» данные мониторинга и понять, как себя «чувствует» тот или иной сервис, понять взаимосвязь между компонентами. Когда мы строим интеграцию, например, с сервис-деском, у вас появляются дополнительные сущности, например, инциденты, проблемы, мы должны их «прицепить» к тем же самым объектам, когда мы говорим об управлении активами, с этими же элементами могут ассоциироваться финансовые составляющие, контракты, договора, стоимость этих активов и т.д.
Таким образом, uCMDB является одним из важных центров. И что важно, мы имеем возможность наполнять uCMDB автоматически, есть отличный метод безагентского дискаверинга, безагентского обнаружения отдельных компонентов инфраструктуры, связей между компонентами, например, мы можем подключиться к базе данных, посмотреть по логам, кто к ней обращался, и таким образом отстроить взаимосвязи между базой данных и ее клиентами. Или, например, когда мы говорим о стандартных приложениях: Active Diary, Microsoft Exchange, заложенный шаблон, мы уже знаем из чего состоит этот сервис, и нам остается обнаружить эти компоненты и простроить все необходимые взаимосвязи. Если есть какой-то сервис нестандартный, внутренней разработки, мы можем создать его модель, и он тоже будет дискавериться автоматически. Автоматический дискаверинг еще важен с той точки зрения, что, обычно, ИТ-инфраструктура современного предприятия очень динамическая, быстро меняется, и, если происходят какие-то изменения, нам нужно их тоже найти, обнаружить, чтобы uCMDB постоянно была up-to-date.
Например, в задачах мониторинга одной из важнейших вещей, которые мы решаем с помощью uCMDB — это корреляция событий. Topology Based Event Correlation — получая массу событий от различных объектов, мы понимаем, как компоненты инфраструктуры влияют на сервисы, соответственно, когда мы получаем поток событий, мы можем определить, какие инфраструктурные события влияют на какие сервисы, выявить причину и следствие этих событий.
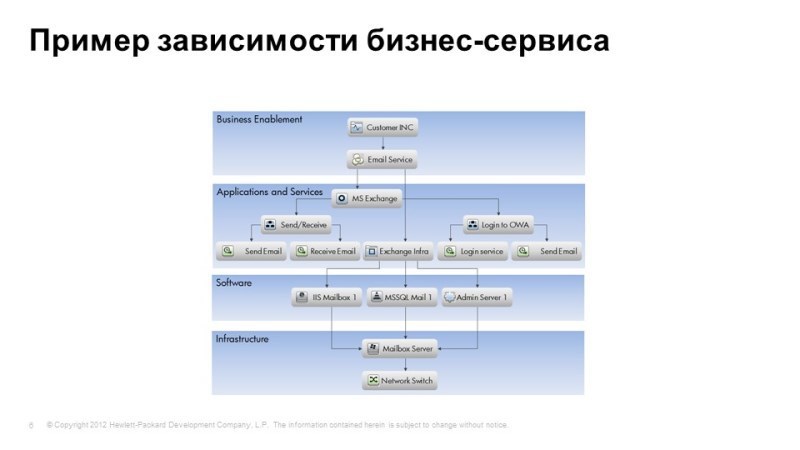
Одно из представлений uCMDB: от уровней инфраструктуры, приложения до уровня бизнес-сервиса.
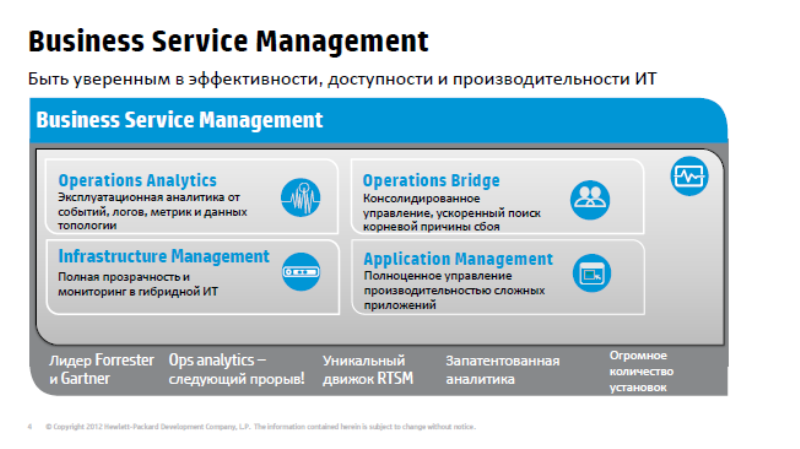
Давайте теперь перейдем более предметно к рассмотрению продуктов, и начнем с группы Application Performance Management. Это те продукты, которые позволяют настроить мониторинг сервисов в целом, понять насколько качественно он работает, работает ли, насколько быстро отвечает, насколько быстро выполняет те или иные функции.
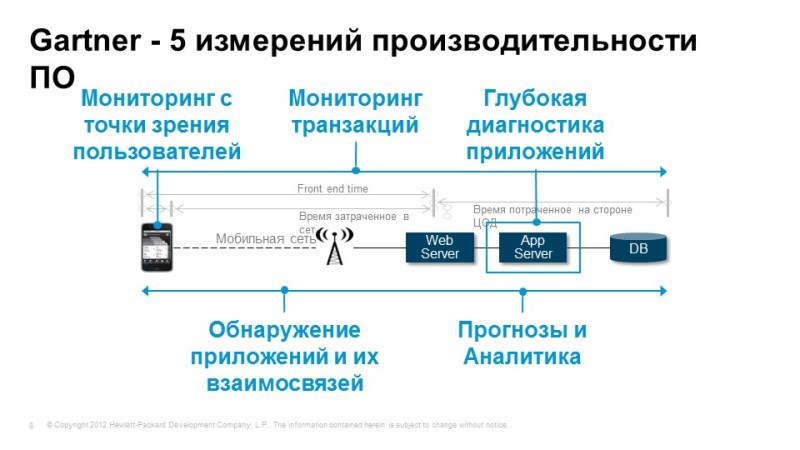
По мнению Gartner, это те вещи, которые должны быть реализованы для решения задач мониторинга производительности приложений. В первую очередь нам нужно иметь возможность мониторинга с точки зрения конечного пользователя. Мы должны понимать, доступен ли сервис для пользователя, как качественно он работает, как быстро работает и работают ли все необходимые функции?
Мы должны иметь возможность отследить прохождение транзакций, когда пользователь выполняет какое-то действие, например, клиент-банк: проверка баланса, ушла транзакция, мы должны понять, куда она пошла, и какие процессы происходят внутри аппликейшин-сервера, и, если возникают какие-либо затруднения, мы сразу можем понять, где возникли эти затруднения. Это могут быть проблемы с приложением, может быть проблема с сетью или базой данных и т.д.
Если же проблема возникает с приложением, нам нужно иметь возможность выполнить глубокую диагностику, понять, что же внутри этого приложения происходит, где происходят задержки, где происходят потери транзакций. Снова же, нам нужно понимать, из чего состоят сервисы, это дискаверинг, автоматическое построение моделей. И конечно же, неплохо иметь возможность прогнозирования, выполнять аналитические задачи для того, чтобы решать нестандартные проблемы и понимать, чего нам ожидать в будущем, как наш сервис будет вести себя завтра или через неделю. Все эти задачи прекрасно решаются с помощью инструментов Hewlett-Packard. Здесь перечислены модули, которые покрывают эти задачи, мы сейчас их и рассмотрим.
User Monitoring
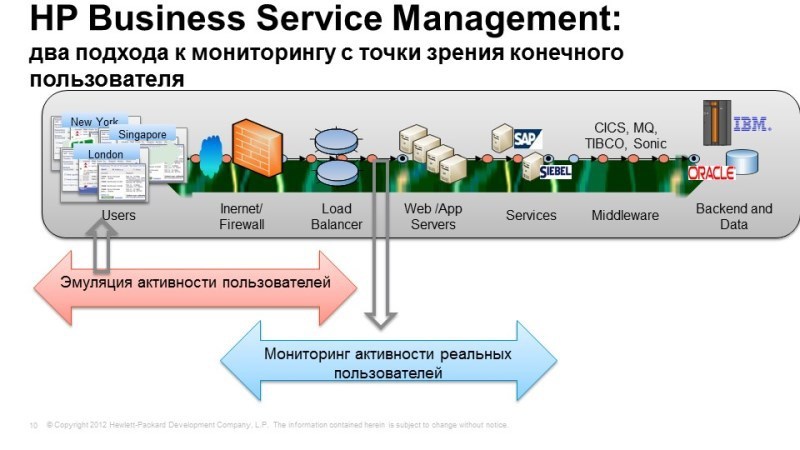
Начнем с мониторинга с точки зрения конечного пользователя. Это решение позволяет получить наиболее быстрый результат при небольших усилиях. Здесь у нас есть два подхода, лучше всего, конечно, их использовать вместе, но возможно и по-отдельности. 1-й вариант – это эмуляция действий пользователя, когда мы под видом реального человека подключаемся к системе, выполняем типичные действия, и смотрим, как они отрабатываются. 2-й вариант – мониторинг активности реальных пользователей, когда мы берем, допустим, систему трафик, содержащий элементы транзакций, как правило, данные берутся из коммутатора, который ближе всего находится к аппликейшн-серверу. Мы копируем трафик и настраиваем его разбор и видим запросы пользователя и видим ответ аппликейшна так мы мониторим доступность сервис-приложений для конечных пользователей.
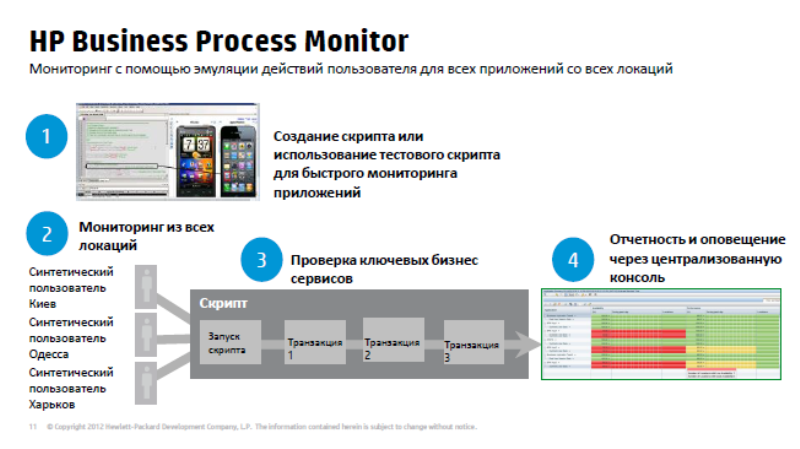
Давайте посмотрим, как это работает. 1-й вариант – это эмуляция действий и активности пользователя. Здесь используется инструмент View Jam, возможно, знаком, способ создания эмуляции действий пользователя. Когда берем, например, консоль, говорим View Jam, что сейчас мы с этой консолью будем подключаться к таким приложениям по таким протоколам. Он перехватывает все наши запросы, все ответы приложения, превращает эти данные в скрипт. Потом мы это параметризуем, допустим, чтобы он соединялся под разными пользователями или выполнял разные типы запросов. Дальше используем этот скрипт, нам уже не нужна консоль приложения, все эмулируется на сетевом уровне, мы можем расставить пробы в любом количестве офисов, внутри нашей сети, и даже вне, и выполнять из этих проб с заданной периодичностью заданные действия. Выбираем необходимые локации, задаем перечень тех действий и транзакций, которые мы хотим проверять, и на выходе имеем консолидированное представление, где показывается из каких локаций происходит подключение, как быстро отрабатываются те или иные транзакции, в одном офисе, другом, третьем, четвертом…
Таким образом, мы видим, как наши системы и сервисы работают в тех точках, где они наиболее важные. В принципе, этот механизм наиболее оптимален для расчёта сулей, поскольку здесь мы сравниваем подобное с подобным. Мы имеем постоянно замеры доступности и производительности приложений по однотипным транзакциям, таким образом легко рассчитать качественный сулей. Этот механизм очень хорош для контроля доступности сервиса, допустим, в нерабочее время, когда реальных пользователей нет, а мы хотим быть уверенны, что наш сервис все так же доступен, например, начался рабочий день в банке, человек пришел, посмотрел, что все необходимые типы транзакций отрабатываются, может спокойно идти пить кофе и не бояться, что сейчас начнут звонить пользователи и что-то у них будет работать не так.
Вопрос: Сколько пользователей может эмулировать максимально?
Неограниченно, как настроите. Тот же механизм используется и для нагрузочного тестирования – weblearn скрипты, у нас есть инструмент LoadRunner. Если нужно сделать нагрузку, можно использовать LoadRunner, а он будет генерировать хоть десятки тысяч одновременных пользователей, поскольку это все делается на сетевом уровне, на уровне протоколов обмена данными, нам не нужна консоль, это очень легкое решение. BPM (Business Process Monitor) хорош тем, что простой в настройке, его можно поставить как stand alone решение, быстро настроить типовые транзакции и, даже не ставя под мониторинг компоненты инфраструктуры, уже понимать, как чувствуют себя наши сервисы, например, показать бизнесу реальное состояние и качество работы наших сервисов.
Он поддерживает огромное количество протоколов, базы данных, аппликейшн-сервера, веб-интерфейсы, толстый и тонкий клиенты, даже для DOS-приложений можно использовать, такого рода мониторинг, для очень устаревших. В Белоруссии в одном из банков пилотировали, у них старое приложение, не проблема даже для этого настроить.
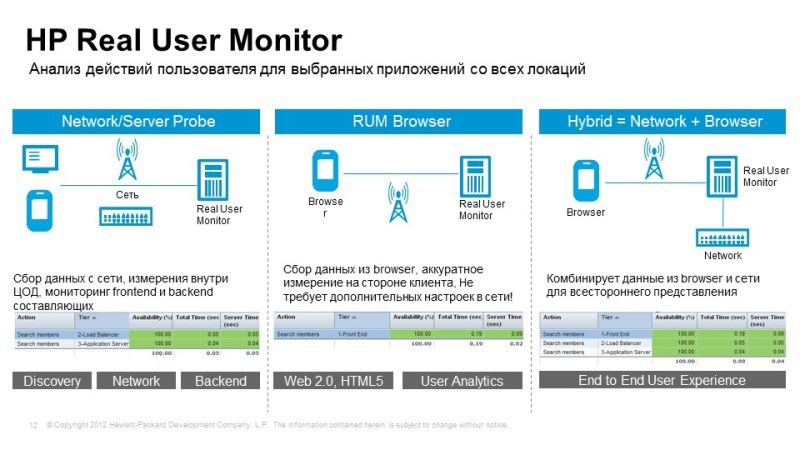
Второй метод, о котором мы говорили – это мониторинг реальных действий пользователей, Real User Monitor, когда мы берем из сетевого трафика или из браузера, из аппликейшн-сервера необходимый сетевой трафик, здесь настраивать не так просто, поскольку нужно поработать с парсинг-трафиком, чтобы выявить элементы тех или иных транзакций, многие вещи делаются автоматически, недавно был пилот в одном из банков: запустили в рум трафик, настроили автоматическое выявление разных типов запросов, и он начал сразу же показывать, что одни запросы обрабатываются быстро, другие обрабатываются полторы минуты. Дальше уже более глубокая настройка,
Что здесь интересно: здесь можно понять, например, для какого конкретно пользователя существует проблема? Если в запросе выявляем пользователей, можем посмотреть, что у какого-то пользователя начались проблемы, можем ему позвонить, сказать ему: “Здравствуйте, мы знаем, что у вас есть проблема, мы над этим работаем, не беспокойтесь, через полчаса все заработает!”
Даже такой уровень сервиса можно сделать с подобными решениями. Здесь же можно делать снепшоты запросов. Когда мы видим, например, информацию об ошибке, какой-то сбой, мы можем снять снепшот, и можем знать, что видит пользователь, конкретную ошибку он видел, и нам не нужно с ним долго общаться по телефону, выяснять, какая проблема у него возникла, собственно, она уже у нас перед глазами.
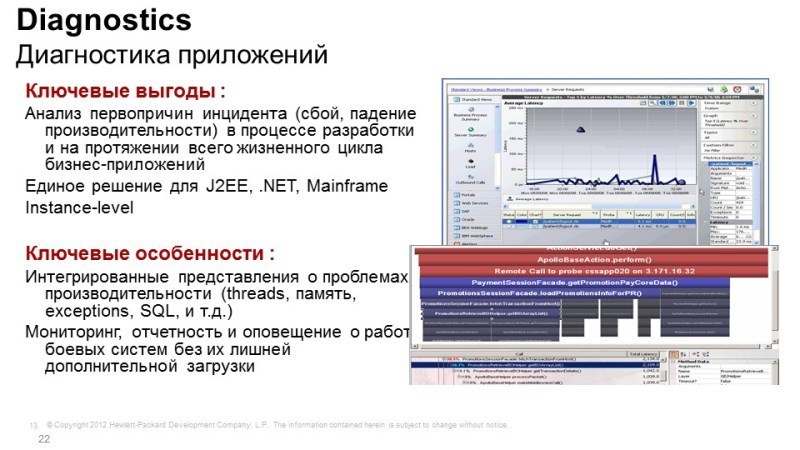
Если же проблемы с работой приложений, кроются глубоко в самом аппликейшине, это не проблема сети, не проблема сервера, а конкретно работы приложений, то тут нам нужны средства диагностики, собственно, решение так и называется HP Diagnostics – это еще один модуль платформы Business Service Management (BSM). Диагностика понимает Java-приложения, .NET-приложения, Python, умеет работать с различными базами данных, и нужна она для того, чтобы заглянуть в глубь. Например, веб-сервер работает, аппликейшн запущен, память гуляет, процессор свободен, диски, вроде, тоже не сильно нагружены, а ответ медленный. Проблема кроется внутри, т.е. в самом приложении.
Средствами диагностики мы можем заглянуть внутрь и понять, что конкретно происходит: пошла транзакция, мы понимаем, какие методы используются, какие функции используются в этом приложении, и можем понять сколько времени занимает обработка того или иного запроса, видим внешние вызовы, вызовы базы данных, видим утечки памяти, можем вплоть до места в коде указать, где кроется проблема, если это внутренняя разработка, если вы тесно сотрудничаете с поставщиком ПО, можно показать ему record ткнуть ему пальцем и сказать: «Вот здесь у вас проблема, решайте».
Если это Oracle, с Oracle мы не так глубоко копаем, но с Oracle тоже можем снимать данные коллектора, коллектор позволяет снять безагентским способом данные и смотреть, что происходит с базами, то есть, Oracle тоже подключается прекрасно.
Сопоставление работы пользователей и компонентов сети
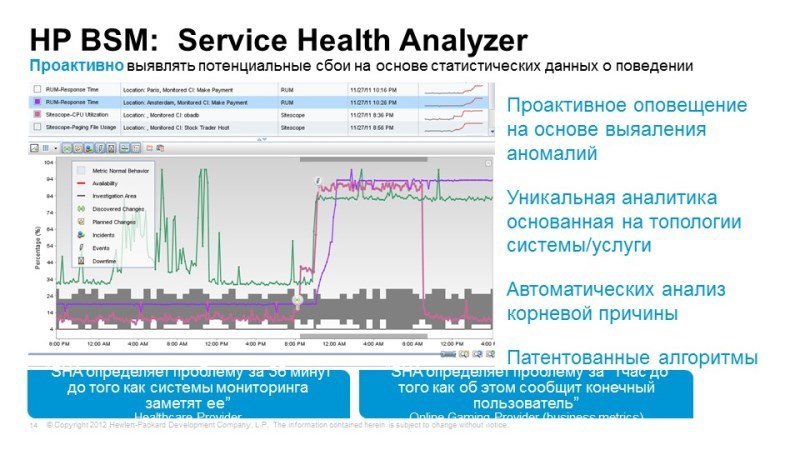
Еще один аспект, который мы не упомянули – это влияние сети. Если мы хотим контролировать то, как влияет работа сети, сетевого оборудования, загрузка канала связи на наши сервисы, то можем использовать Network Node Manager, он также тесно интегрируется в нашу платформу, позволяет понять, чем грузятся каналы, как работа сети или состояние того или иного оборудования и даже изменение конфигурации этого оборудования влияет на работу и доступность наших сервисов.

Таким образом, BSM (Business Service Manager) позволяет создать единое консолидированное представление содержащее информацию о том, какие у нас сервисы используются, как они себя чувствуют, как себя чувствуют отдельные компоненты. Этот портал хорошо кастомизируется, в принципе, под каждую конкретную роль можно создать одно или несколько представлений. Пользователи, конечно, ограничиваются теми сервисами, за которые они отвечают и теми инструментами, которые для них доступны, даже рядовой пользователь сам для себя, используя простой графический конструктор, может набросать то представление, которое ему интересно. Или же можем для наших пользователей создать ряд представлений, которые будут использоваться для решения тех или иных задач.
Operations Bridge
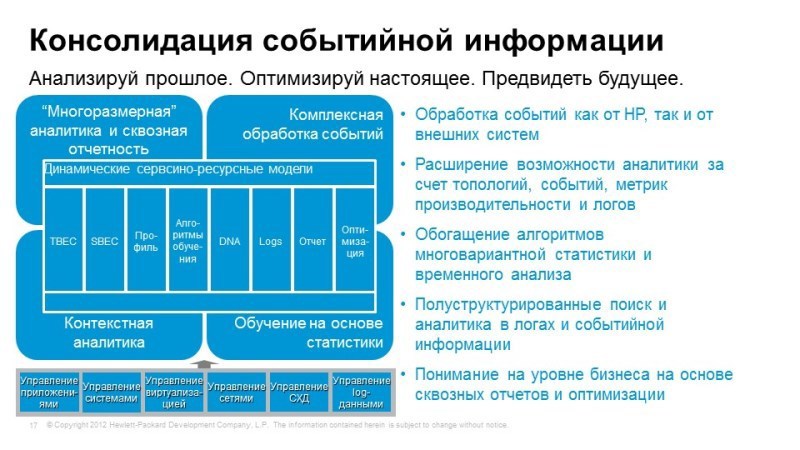
Следующая тема, о которой мы поговорим – это Operations Bridge/Зонтик. Представим, что у нас уже теми или иными способами решена задача мониторинга, мы мониторим сеть, мониторим системы хранения и передачи данных, программное обеспечение, и делаем это все разными инструментами. HP не HP – не важно.
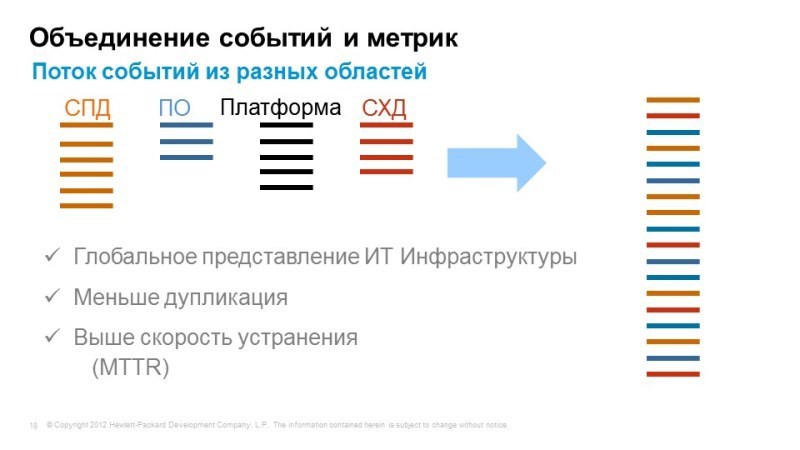
Но у нас нет единой консоли, которая показывает работу всех сервисов в одном окошке. Для того, чтобы решить эту задачу, предлагаем использовать Operations Bridge, которая берет события, берет информацию о топологии приложений из самых разнообразных систем, объединяет это все в единой консоли и позволяет коррелировать все эти события для того чтобы выявить причины, симптомы.
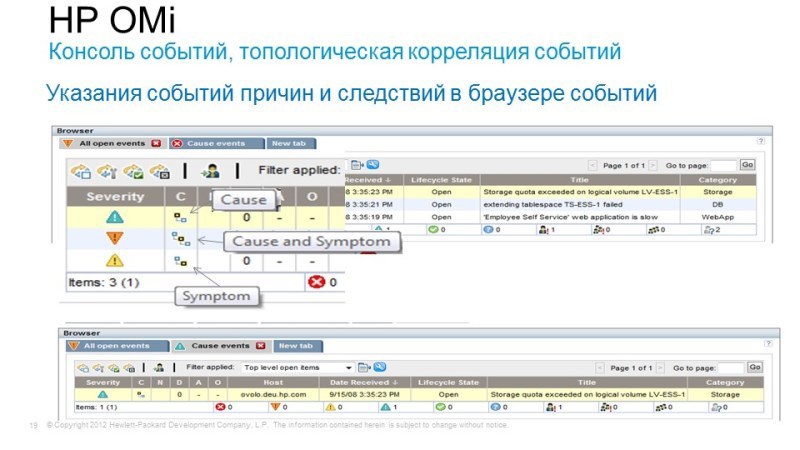
Например, пользователь заходит на интернет-банкинг, пытается выполнить какую-то транзакцию – у него не получается. Не получается потому, что база данных сбоит, а сбоит потому что не удалось расширить дисковые пространства на дисковых массивах. Т.е. проблема, которая нас беспокоит – это недоступность или некачественная работа интернет-банкинга, а причина кроется где-то далеко в СХД. Operations Bridge как раз позволяет объединить, скоррелировать все эти события, используя интересные методы корреляции: во-первых – это Topology Based Event Correlation, когда мы имеем uCMDB топологию сервисов, и в зависимости от того, с какими компонентами связан тот или иной сервис, можем понять как влияют те или иные события на его доступность. Поскольку модель uCMDB у нас динамичная, что-то поменялось – изменяя дискаверинг, автоматически перестраиваются правила корреляции. И второй метод — Stream Based Event Correlation, когда по времени возникновения тех или иных событий, мы можем предположить, что они связаны между собой, а также выявить, что является причиной и следствием.
Таким образом можем объединить в единой консоли все события, объединить все QPI, которые нас интересуют, и сделать эту консоль центральной системой мониторинга. Когда нам уже нужна более детальная информация, можем углубиться в ту систему, из которой мы получили эти данные мониторинга.

Что еще интересного позволяет делать Operations Bridge – автоматизировать настройки мониторинга при помощи средства Monitoring Automation, встроенного в Operations Bridge. Он позволяет, например, создавать типовые настройки мониторинга для тех или иных сервисов.
Например, добавилась у нас БД Oracle, можем автоматически направить, поставить под мониторинг с использованием типовых и стандартных шаблонов. Или же изменилась топология сервисов, переехал он на другую платформу, другой гипервизор – изменить правила мониторинга, чтобы система мониторила именно то, что сейчас происходит, не что происходило неделю назад.
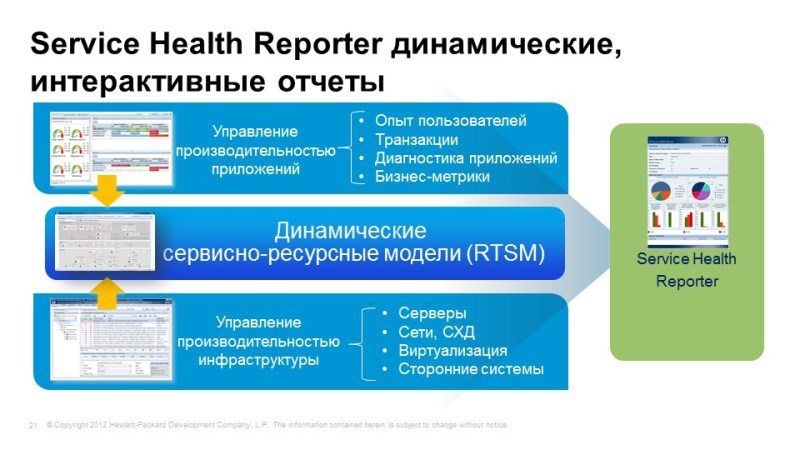
И, конечно же, отчетность. В Operations Bridge входит Service Health Reporter, который позволяет объединить метрики из различных систем и строить консолидированные отчеты, снова же, с привязкой к бизнес-сервисам, к дежурным сервисным моделям. Что-то поменялось – отчеты, следовательно, тоже будут автоматически перестраиваться. В коробке большое количество, около тысячи, различных отчетов, и соответственно, можно создавать свои.
Operations Analytics
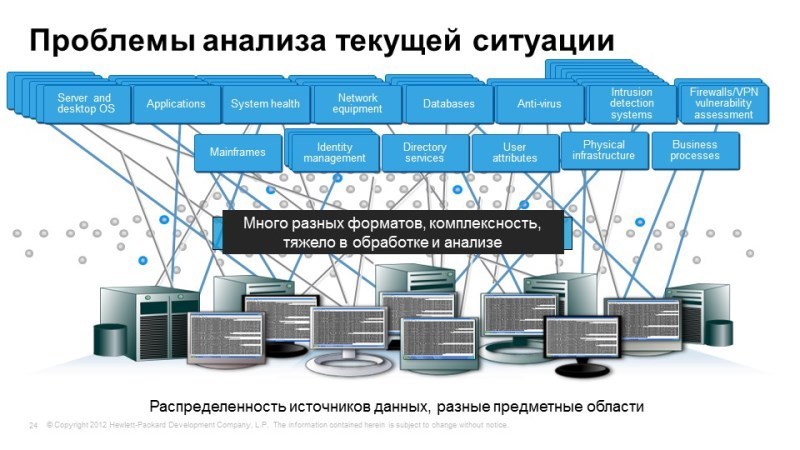
И третья вещь, о которой хотели поговорить: Operations Analytics. Как я уже говорил, когда мы используем традиционные средства мониторинга, мы знаем, что хотим мониторить, самих событий происходит значительно больше, чем мы можем предугадать, на гигабайты логов, которые у нас хранятся, или на огромное количество данных производительности было бы неплохо иметь возможность их всех объединить, нам нужно интеллектуальное и умное средство для работы со всей этой информацией, чтобы выявлять нестандартные ситуации. Operations Analytics использует технологию BigData, так, например, в качестве базы данных используется вертика (слышали про вертику?). Расскажем в двух словах.
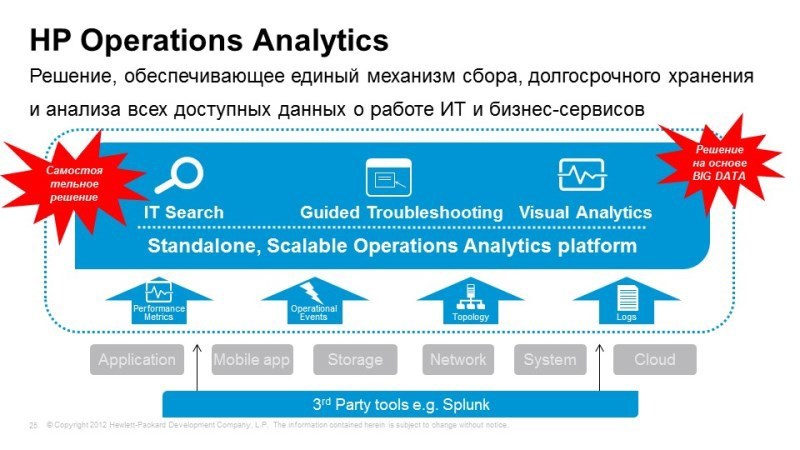
Что Operations Analytics делает? Мы на него направляем все логи, все данные производительности. Все эти данные приводятся к единому формату. Operations Analytics позволяет хранить все логи, данные производительности и позволяет строить временную корреляцию между событиями, позволяет посмотреть на то, как чувствовал себя сервис в любой момент времени.
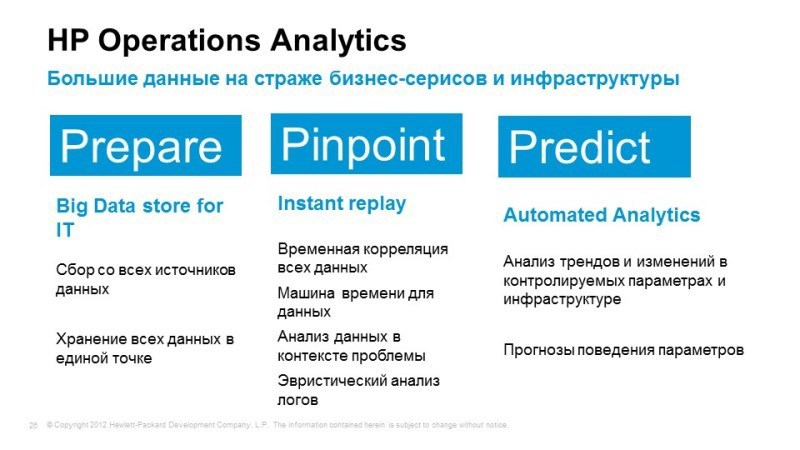
Механизм машины времени позволяет перемотаться в тот момент, когда происходил сбой и посмотреть, какие события происходили в этот момент, какие, например, были показатели производительности, загрузки каналов, и т.д. и определять тенденции, строить прогнозы по состоянию наших сервисов.
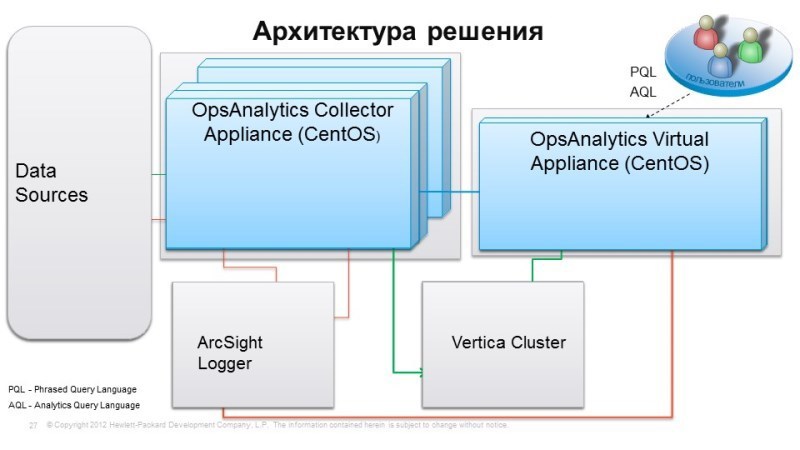
Архитектура: Vertica

Если посмотреть на архитектуру решения, она состоит из следующих вещей: для хранения данных используется Vertica – это БД, предназначенная для работы с большими данными, позволяет загружать огромное количество информации, обладает колоссальной масштабируемостью. Vertica интересна тем, что она создана для того, чтобы работать на дешевом оборудовании, она работает на х86-серверах, данные хранит на встроенных дисках и позволяет получать, практически, линейный прирост производительности при масштабировании. Было у нас, допустим, 3 сервера, мы их увеличили до 6, производительность вырастает вдвое и так, в общем, без ограничений. Например, Вертику использует Facebook c их колоссальными объемами данных,
Для сбора данных, работы с логами мы предлагаем с OpsAnalytics использовать ArcSight Logger. Это решение родом из информационной безопасности. ArcSight Logger хорош тем, что уже имеет массу коннекторов к самым разнообразным системам, уже умеет изначально собирать самые разнообразные логи и позволяет писать коннекторы для тех систем, к которым у нас их нет. Построена аналитическая настройка и есть связь с data sources, т.е. это система мониторинга НР или не НР, которая позволяет грузить туда события, метрики и т.д. Таким образом, мы в одной системе объединяем данные мониторинга, из систем мониторинга объединяем логи, и можем делать интересный анализ при помощи этого инструмента. Простая, понятная и очень производительная система.
Изначально Vertica лицензируется по объемам загружаемых в нее данных. Не важно сколько серверов. В комплекте с OpsAnalytics Vertica на 4Тб. Если этого объёма мало, тогда нужно дополнительно покупать лицензию Вертики.
Когда мы говорим про мониторинг логов тем же самым Conection Manager, агентом системы мониторинга, который выискивает заданные события, обработка логов может производится на самом объекте мониторинга. Мы периодически смотрим лог-файлы, когда видим нужное событие, отсылаем в систему. А здесь он работает по-другому. Здесь мы забираем полностью все логи в онлайн режиме и их разбор уже происходит уже на стороне OpsAnalytics. Т.е. здесь немного другого рода нагрузка. Если система мониторинга, тот же BPM, будет мониторить транзакции, то в сторону OpsAnalytics уйдет конкретная информация по транзакциям. Для того, чтобы объединить все это с информацией в логах, и посмотреть, какие события в логах могли вызвать сбой или ухудшение качества сервиса.

ArcSight Logger – это хороший выбор с точки зрения сбора логов, поскольку это решение уже не один год на рынке, уже существует масса коннекторов к разнообразным системам, есть удобный инструмент разработки своих коннекторов, чтобы два раза не изобретать велосипед, логи как раз и используются для сбора данных. Если вам нужно, можно использовать спланк.

Таким образом, что мы получаем? Получаем возможность выявления событий в логах, которые влияют на работу и производительность наших сервисов. Например, мы увидели ухудшение времени доступности сервиса, автоматическая система позволяет выявить те события в логах, которые могут быть причиной этого. Система выявляет новые, нестандартные события, предоставляет удобный инструмент для работы с логами, т.е. по контекстному поиску, — хороший механизм поиска, когда набираем отдельные элементы, поиск похож на человеческий язык. Она позволяет прогнозировать поведение наших сервисов в зависимости от того, как ведут себя те или иные компоненты, и позволяет, например, объединить данные ИТ-мониторинга с “неайтишным” мониторингом.
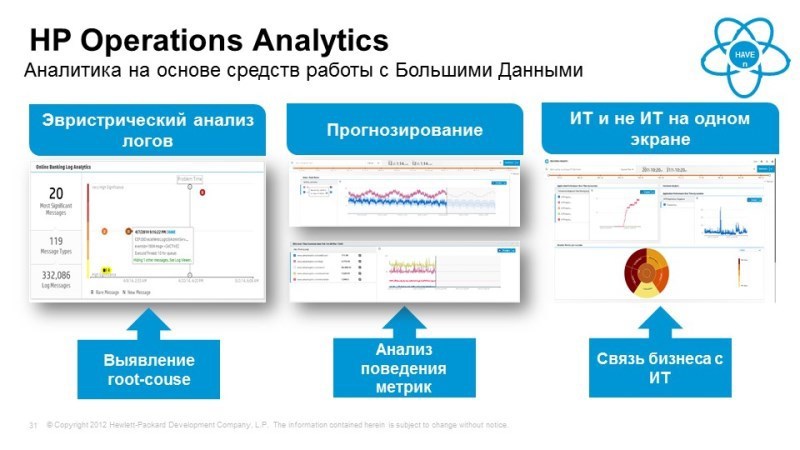
Как один из примеров, банк в одной из Европейских стран имел широкую сеть, в том числе и в горной местности, и у них периодически наблюдались непонятные ухудшения работы их сервисов в определенных регионах, они не могли определить причины возникновения. Кто-то додумался прикрутить в аналитику еще данные о погоде, и выявили стойкую взаимосвязь между состоянием окружающей среды, ветром, осадками и сбоем. Соответственно, нашли те места, которые и страдали от плохой погоды.
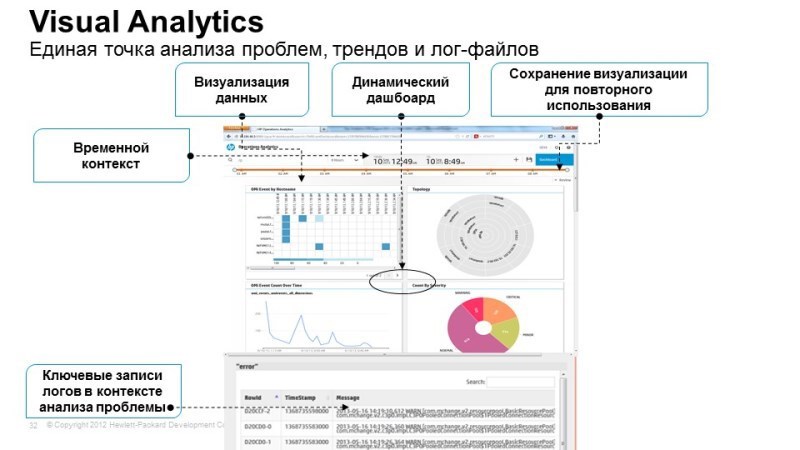
Интересный инструмент в аналитике – это машина времени. Вы видите вверху временную консоль. Система позволяет перемотаться в любой момент времени на временной консоли, а внизу будет отображаться то, как себя чувствовал сервис в данный момент времени, какова была производительность по определенным его функциям и какие события происходили в логах в тот момент времени, который нас интересует. Таким образом можем перематывать фактически в реальном времени, видеть, как изменялось состояние сервисов, какие события происходили, как менялись те или иные параметры производительности. Все эти данные хранятся в вертике и мы в реальном времени получаем из нее интересующие нас данные.
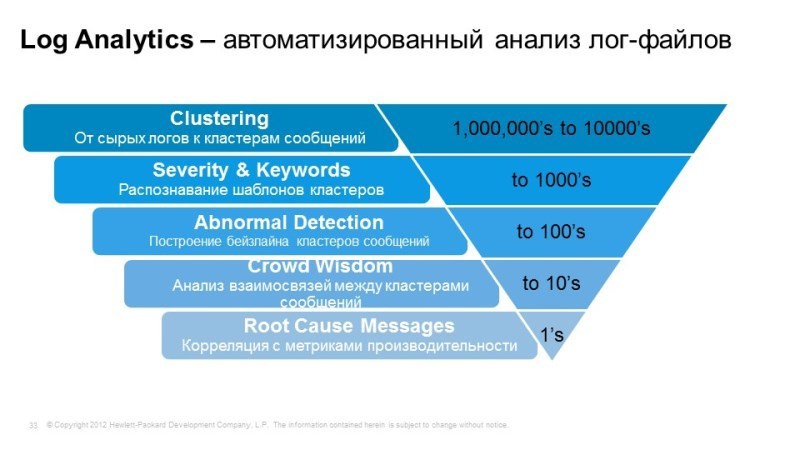
Одна из основных задач – это работа с большим количеством логов и выявление тех событий, которые либо являются причинами, либо потенциальными причинами сбоя. Мы выгрузили туда гигабайты логов, а на выходе имеем лишь несколько событий, которые система посчитала потенциально важными или потенциально важными для работы сервиса.
Небольшое демо (из доклада)
Оператор получил информацию по определенным транзакциям, есть у нас ненормально большой респонс-тайм. Открылась консоль, где показывается респонс-тайм, соответственно, красный – традиционно плохой. Общее состояние сервиса и метрики по определенному компоненту, например, Application Performance Overtime, и финансовые метрики, не имеющие прямого отношения к ИТ.
Такой вот флешбек позволяет управлять воспроизведением, и мы можем управлять воспроизведением, перемотаться в прошлое, посмотреть, как изменялись эти показатели, как менялись респонс-тайм транзакций и как чувствовал себя сервис и информацию по другим метрикам. Нашли момент, когда все работало хорошо, с этого момента стало плохо, нажали паузу, перематываемся, и можем смотреть влияние системных ресурсов на этот сбой, а также события логов, при этом, конечно, отображаются не все события, а только те, которые система посчитала важными. Из 93 тысяч логов событий у нас осталось 20, которые потенциально могут влиять на появление этой проблемы. Смотрим на этот лог, видим, это событие, можем нажать ок, чтобы в следующий раз это событие конкретно выискивалось.
Проблема оказалась в неправильной конфигурации лоджика. Это оператор догадался по типу ошибки. Можем добавить информацию о Transaction Performance Overtime к финансовым метрикам, которые здесь отслеживаются для того, чтобы выявить взаимосвязь. и предлагает нам скоррелировать эти события. Вот, нагрузили ему несколько метрик и предлагает скоррелировать. Здесь мы видим связь между показателями. Очень видимая связь наблюдается между Application Transaction Response Time и количеством отдельных пользователей, количеством пользовательских подключений.
В общем, мы видим, что конфигурация веблоджика влияет на те или иные показатели.
Вернулись снова в текущее положение, теперь на предлагает нажать на Predict и посмотреть, как мы ожидаем развитие событий.
Это настроенный дашборд для мониторинга Advent Rebanking – онлайн-банкинг, данные берутся оттуда. Изначально это предконфигурированный дашборд, мы набросали те метрики, за которыми следим, и те объекты, которые нам интересны.
Мы смотрим на нетипичные события, если что-то стало проявляться нетипично, нестандартно, значит нам это потенциально интересно. Если же написан error, тоже наверняка интересно.
Видеозапись доклада:
http://youtu.be/z2UzmUq9pw4


")



Релоцировались? Теперь вы можете комментировать без верификации аккаунта.